Search Engine Index
April 14, 2024
Building an Inverted Index Search Engine
I recently undertook a project to develop a custom information retrieval system designed to search through a large corpus of text documents. The primary goal was to create a high-performance search engine capable of handling various search techniques, including basic Boolean search, Phrase search, Proximity search, and Ranked IR, all while utilizing an inverted index structure.
System Architecture
The system was implemented in Python 3 and leveraged the Porter stemmer from the NLTK package. To optimize the search performance, I developed custom tokenization and filtering strategies tailored to the specific characteristics and vocabulary of the target document corpus.
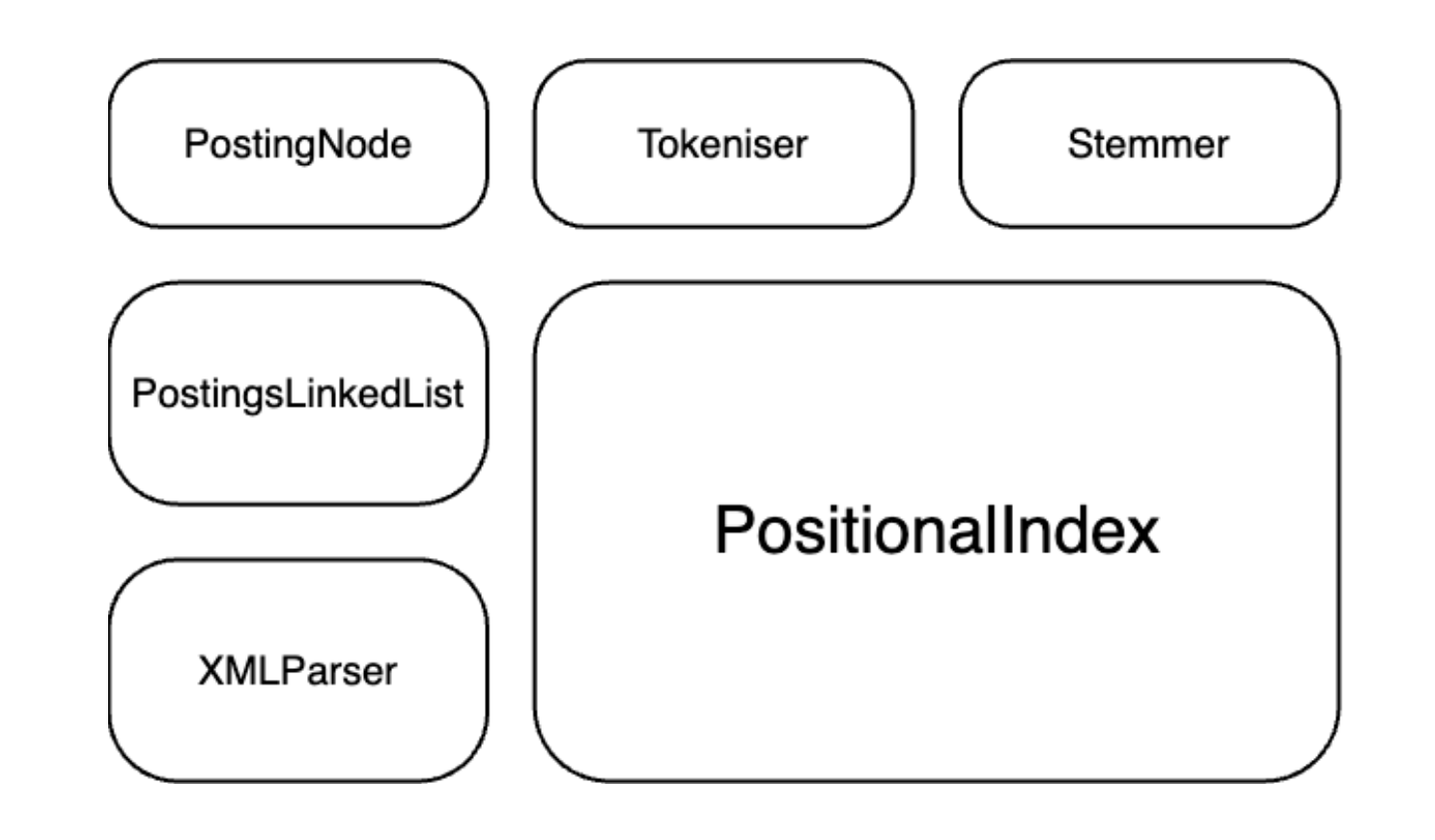
The system consists of five main components: Document Ingestion, Tokenization and Stemming, Inverted Index, Query Processing, and Retrieval. By abstracting these components into separate modules, I aimed to create a modular and reusable system that could be easily updated and maintained.
Corpus Processing
One of the key aspects of the system was efficient document ingestion. Instead of reading the entire XML file into memory, I utilized the xml.etree.ElementTree.iterparse function to process documents one by one, reducing memory usage. This approach also proved to be more resilient to formatting errors in the XML file, ensuring that correctly formatted documents could still be loaded even if some were malformed.
The tokenization module was designed as an independent component with adjustable settings, allowing for fine-tuning of preserved regex patterns, lowercasing, number exclusion, minimum token length, and token caching. These features were instrumental in optimizing the tokenization process based on the specific needs of the document corpus.
Inverted Index and Query Processing
The inverted index lies at the heart of the search engine, enabling fast retrieval of relevant documents for a given search query. I implemented a dictionary structure to map preprocessed and stemmed terms to the documents containing them, along with a PostingsLinkedList (PLL) to store the document IDs and positions efficiently.
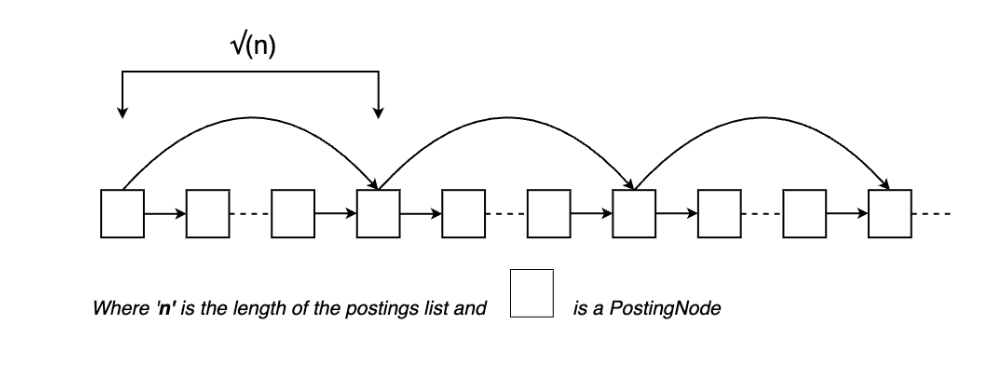
The choice of using a PLL was motivated by potential performance gains during query time. By keeping postings in sorted order and incorporating skip pointers, I aimed to expedite the traversal of postings lists and reduce the average time complexity of merge operations.
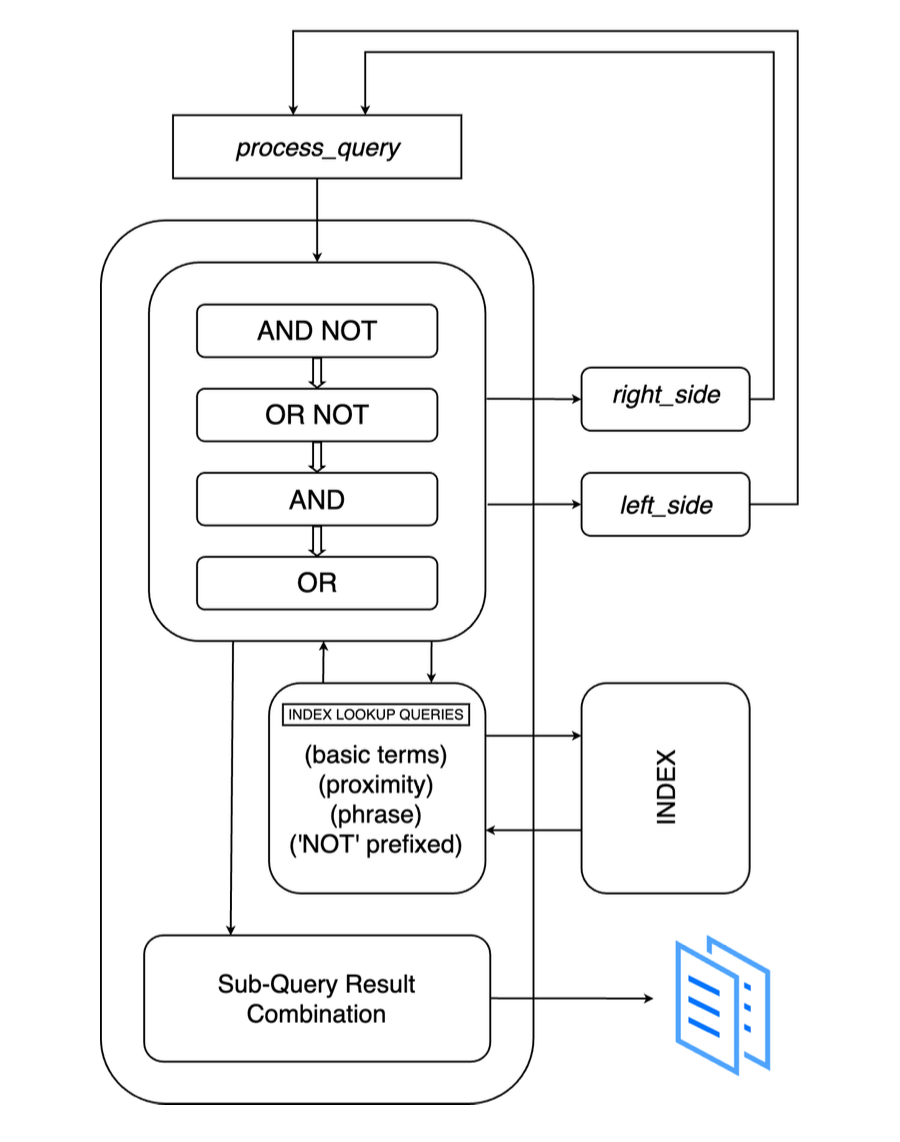
Query processing involved parsing the user’s query and matching it against a hierarchy of patterns to identify specific keywords. The query parser recursively breaks down the query until it reaches the base cases, applying appropriate logic for each pattern encountered. This approach allows for handling complex boolean queries with multiple keywords.
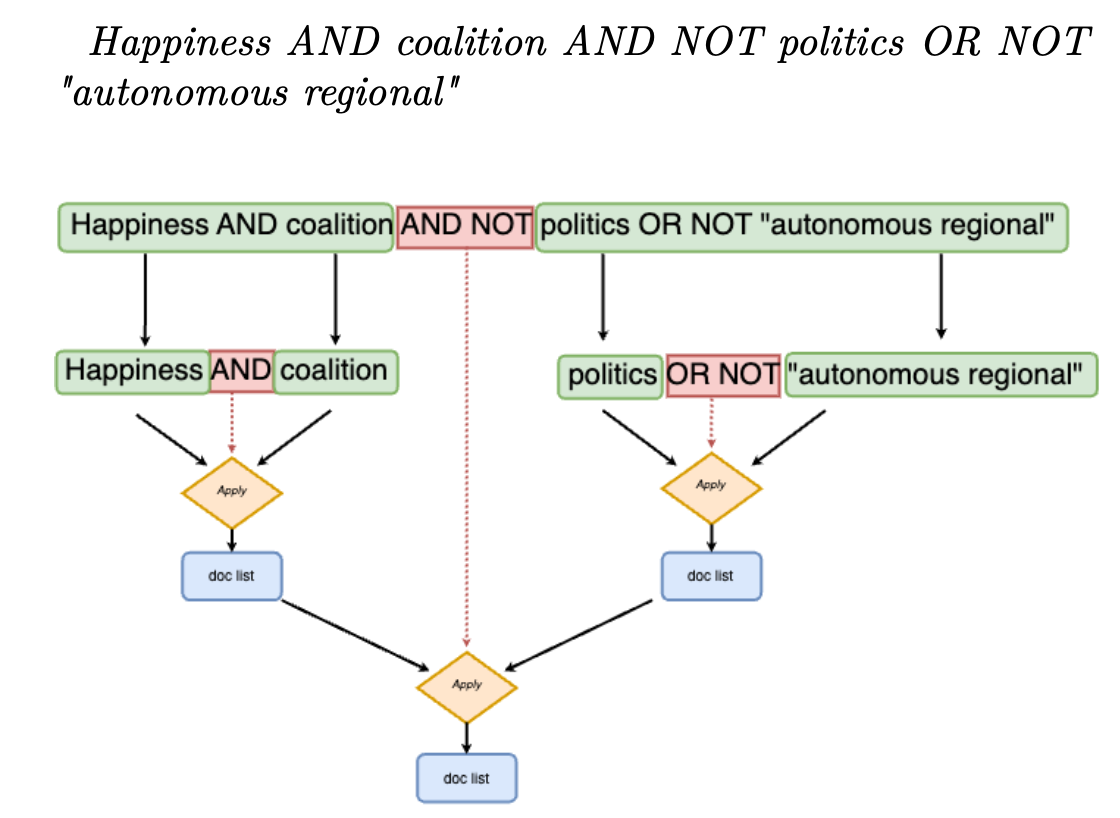
An example breakdown could be:
Part II
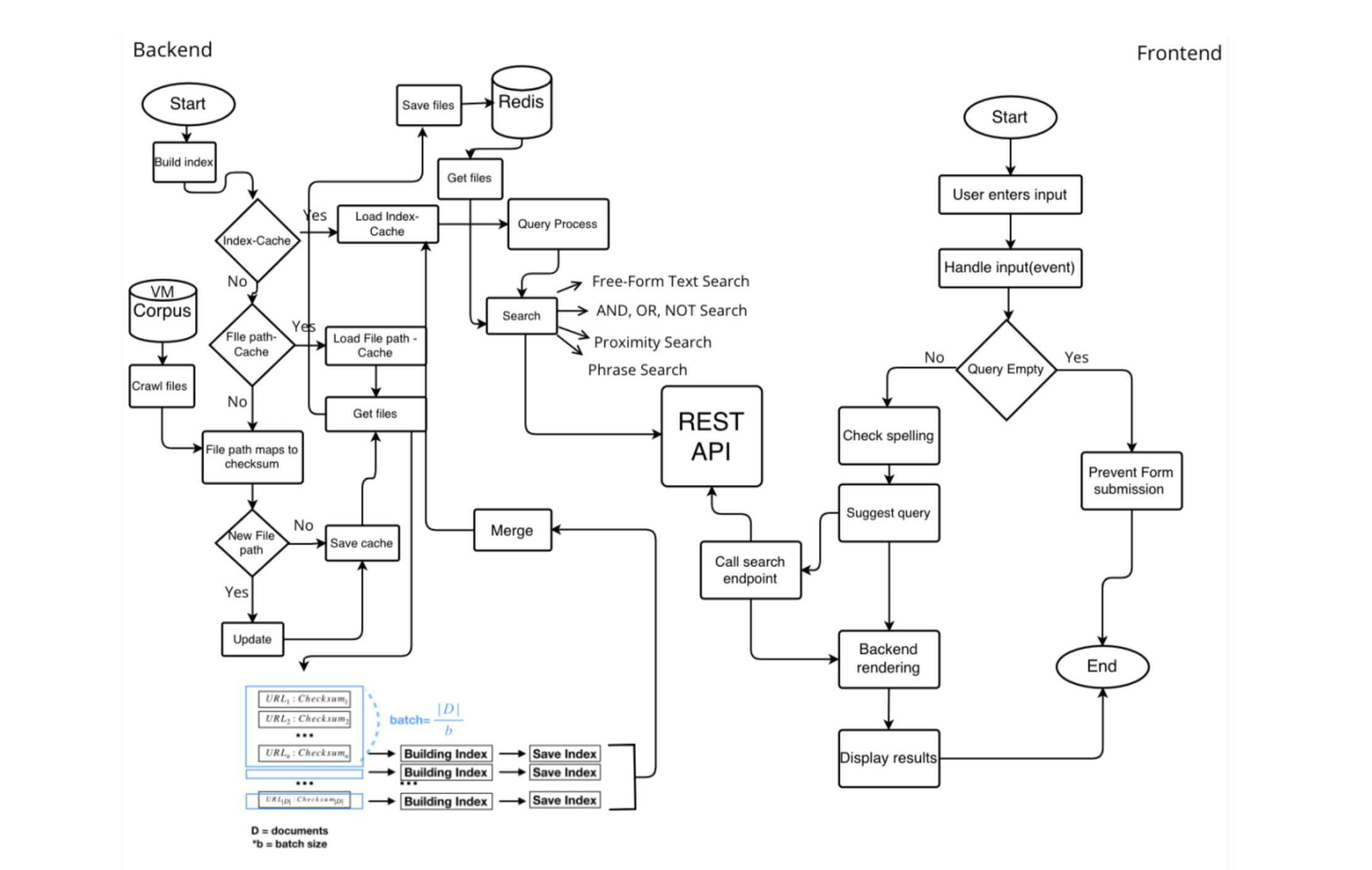
The second part of this project was to build a fully self-contained search engine in team of 6. It should have search, indexing, crawling, and liveness features as part of its core functionality. I can provide a snippet showing my contributions to this aspect, but will not provide the entire report publicly as the assessments may be repeated, and this could be plagiarized. I will, however, provide a link to request accesshere.
Statement of Contributions (excerpt from the report)
I worked on developing the backend of the search engine, particularly the positional index and its optimizations. This was driven in part by familiarity with our starter code (we had collectively agreed to use a version subset of the indexing code I had submitted as part of the coursework). I then worked on the Positional Index and Postings Linked List classes, forming the foundation of the indexing system. Later implemented a trie-based IndexTrie and relevant search, update and posting intersection algorithms to improve memory efficiency and overall performance. I also worked on the Crawler class for document location indexing and tracking. This included keeping checksum values to queue files for reindexing, if the content had changed.
More general tasks included building an execution pipeline for the positional index. The pipeline encompasses document crawling, preprocessing, tokenization, postings creation, index updates (saving and building), and metadata management. During the later stages of the project, I optimized the indexing process by implementing concurrency and batch processing to parallelize indexing tasks via process pools encapsulated in a thread pool. Additional changes included implementing checkpointing and index merging mechanisms as fail-safes to improve efficiency and reliability, resulting in better resource utilization.